复现广发证券《基于日内高频数据的短周期选股因子研究》
我是聚宽的一梦春秋,这篇文章首发在聚宽,是我参加聚宽第一届研报复现比赛的获奖作品,获得了第一名。
作者:@一梦春秋 (公众号春秋金经)
个人介绍:知我者,谓我心忧;不知我者,谓我何求。
1 引言
研究目的:
本文参考广发证券《基于日内高频数据的短周期选股因子研究-高频数据因子研究系列一》,对研报构造的因子做了实现,并复现了里面的结果,做出了分析。其中用个股日内高频数据构造选股因子,低频调仓的思路是一个很好的方向。
研究内容:
基于个股日内高频数据,构建了已实现波动(Realized Volatility) 𝑅𝑉𝑜𝑙,已实现偏度(Realized Skewness)𝑅𝑆𝑘𝑒𝑤、已实现峰度(Realized Kurtosis)𝑅𝐾𝑢𝑟𝑡因子指标,考察这三个因子在回测区间内对个股收益率 的区别度。
研究结论:
在三个因子中偏度RSkewRSkew因子最有效,分组区分度高,比较稳定,收益最高。
2 因子构建
因子构建过程摘自研报,具体因子指标构建如下:
对于每个个股在交易日t,首先计算个股在特定分钟频率下第i个的收益率 rt,irt,i, rt,irt,i = pt,ipt,i − pt,i−1pt,i−1,其中pt,ipt,i表示在交易日t,个股在第i个特定分钟频率下的对数价格,pt,i−1pt,i−1表示在交易日t,个股在第i−1个特定分钟频率下的对数价格。
对于每个个股,根据𝑟𝑡,𝑖分别计算个股在交易日t下的已实现方差(Realized Variance) RDVartRDVart、已实现偏度(Realized Skewness) RDSkewtRDSkewt,已实现峰度(Realized kurtosis) RDKurttRDKurtt。其中:
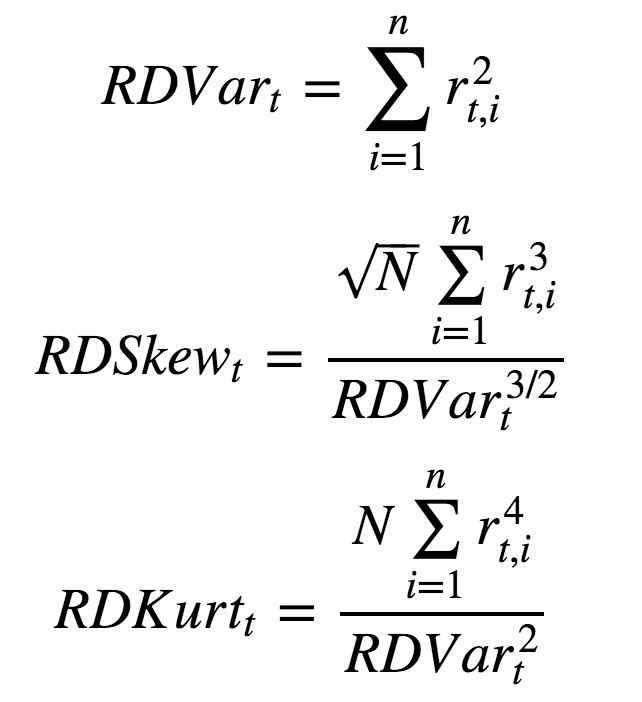
其中N表示个股在交易日t中特定频率的分钟级别数据个数,如在1分钟行情级别下,数据个数N为60*4=240;在5分钟行情级别下,数据个数N为240/5=48。
对于每个个股在交易日t计算累计已实现波动(Realized Volatility)RVoltRVolt, 已实现偏度(Realized Skewness)RSkewtRSkewt、已实现峰度(Realized Kurtosis) RKurttRKurtt ,其中:
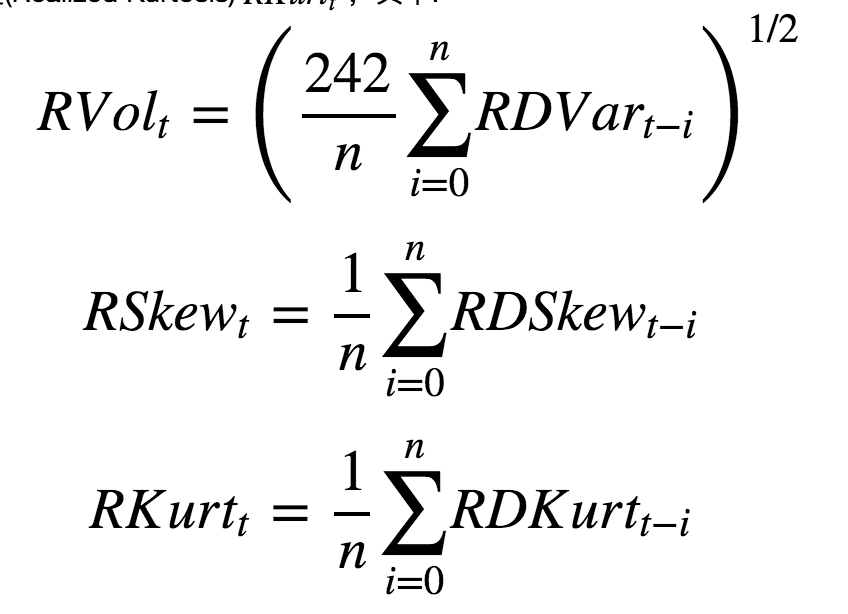
在每期调仓日截面上,按照上述公式计算每个个股的已实现波动(Realized Volatility)RVoltRVolt,已实现偏度(Realized Skewness)RSkewtRSkewt、已实现峰度(Realized Kurtosis)RKurttRKurtt指标,针对每个由高频数据计算得到的因子指标在历史上的分档组合表现,试图寻找出相对有效的因子指标。
3 构造因子数据
计算因子值的过程比较慢,大概耗时1小时左右。如果直接下载我构造好的数据文件(factor_dict.pkl)上传到研究里可以跳过这一步,直接到因子特征展示开始执行。
以下开始计算因子值:
import pandas as pd
import numpy as np
from jqdata import *
import math
from pandas import *展开代码 ↓
# 获取某个交易日的因子值
def get_one_trade_day_data(cache = {}, stocks = None, trade_date = None):
# print(trade_date)
_\# 后面需要在交易日t计算累计已实现波动等数据,需要获取交易日t到交易日t-n之间的交易日_**展开代码 ↓**
# 按照研报要求,去除上市不满一年的股票,剔除ST股
def filter_stock(stocks, date):
# 去除上市距beginDate不足6个月的股票
stock_list = []
for stock in stocks:展开代码 ↓
# 获取样本区间内的因子数据
# 研报中样本区间:2007年1月1日至2019年3月27日
# 2007-2019数据实在太多了,这里减一半,使用2013-2019,也一样涵盖牛市和熊市
start_date = date(2013, 1, 1)展开代码 ↓
2013-01-04
2013-01-11
2013-01-18
2013-01-25
2013-02-01展开输出 ↓
# 把计算出的因子数据写入文件 方便后续调用
import pickle
pkl_file = open(‘factor_dict.pkl’, ‘wb’)
pickle.dump(factor_dict, pkl_file, 0)展开代码 ↓
4 因子特征展示
通过上文中的代码,已经获取到了中证500成分股2013-2019的因子数据。
以下分别从因子频率分布、因子百分位走势2个维度展示因子特征。
1 频率分布
import pickle
import matplotlib.pyplot as plt
import numpy as np
展开代码 ↓
market_vol = []
market_skew = []
market_kurt = []
for date in factor_dict:展开代码 ↓
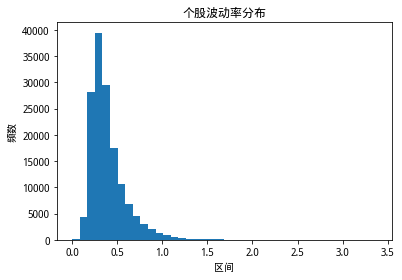
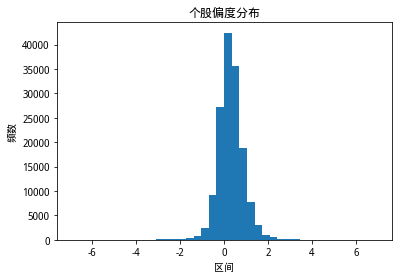
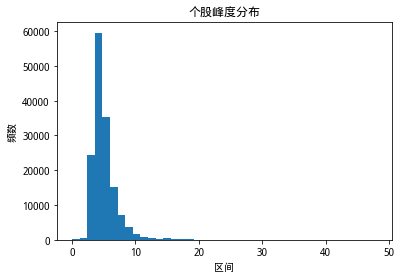
从以上因子分布三图看出,整个A股市场个股的波动率分布整体上呈现右偏分布;个股的偏度分布,整体偏度水平保持在零附近,呈现较为明显厚尾状态;个股的峰度分布与个股波动率水平类似,分布整体上右偏,且样本内个股的峰度水平大部分大于3,呈现厚尾的现象。
和研报中的三个因子分布图情况和结论相同。
2 百分位走势
# 显示因子百分位走势
def show_percent_factor_value(factor_dict, factor_name, legend_loc):
# 百分位走势5档颜色 蓝 橙 绿 红 紫
color_list = [‘#5698c6’, ‘#ff9e4a’, ‘#60b760’, ‘#e05c5d’, ‘#ae8ccd’]
展开代码 ↓
# ‘r_vol’, ‘r_skew’, ‘r_kurt’
show_percent_factor_value(factor_dict, ‘r_vol’, ‘upper left’)
show_percent_factor_value(factor_dict, ‘r_skew’, ‘lower left’)
show_percent_factor_value(factor_dict, ‘r_kurt’, ‘upper left’)
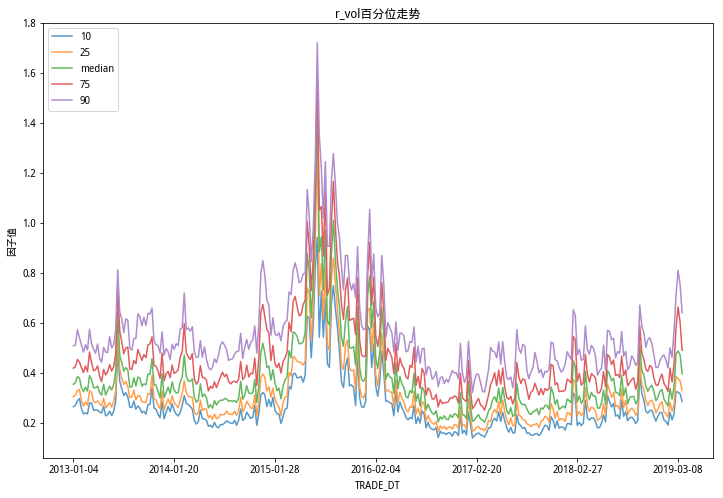
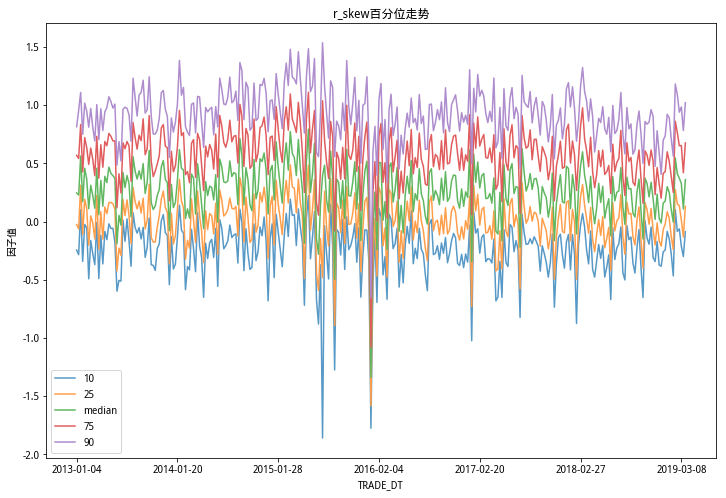
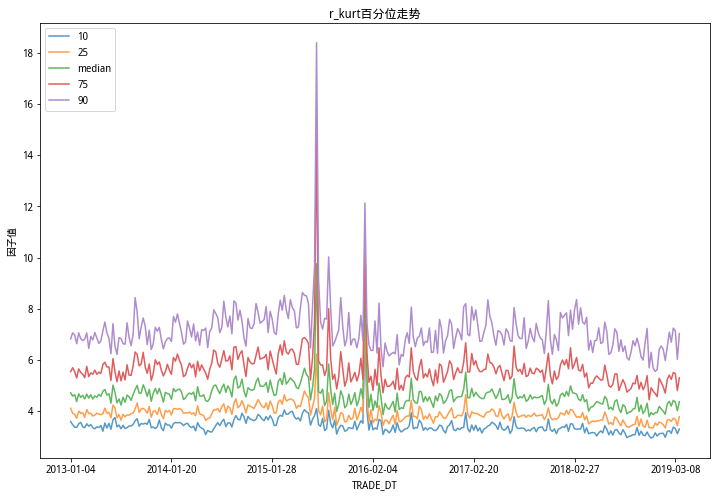
从以上三图看出,个股的波动率在不同的时间维度上变化较大,当市场趋势行情较明显时候,个股波动率水平整体上呈现上升的趋势;个股偏度水平整体较为稳定;个股峰度水平在极端行情下峰度更高,且不同分位数差异更加明显。
和研报中的三个因子百分位走势图情况和结论相同。
5 实证分析
1 因子选股分档表现
def group_df(df, count):
length = int(len(df) / count)
groups \= \[\]
**for** i **in** range(0, count \- 1):**展开代码 ↓**
# 求每天的收益率
import pandas as pd
ret_df_index = []
ret_df_data = []展开代码 ↓
# ‘r_vol’, ‘r_skew’, ‘r_kurt’
show_factor_level_return_rate(ret_df, factor_dict, ‘r_vol’)
show_factor_level_return_rate(ret_df, factor_dict, ‘r_skew’)
show_factor_level_return_rate(ret_df, factor_dict, ‘r_kurt’)
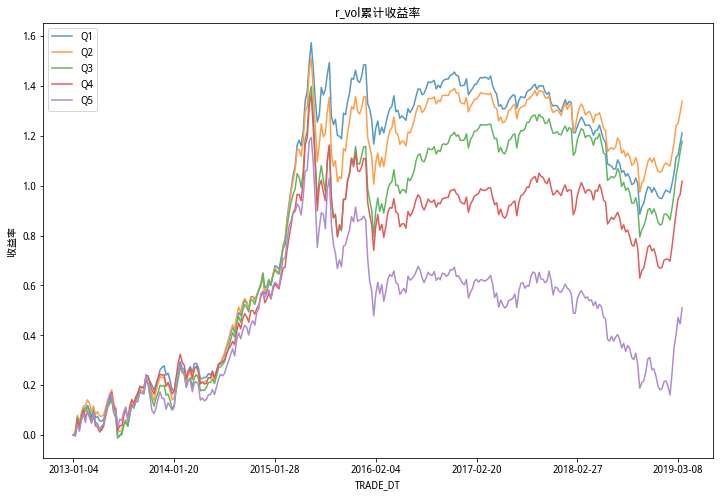
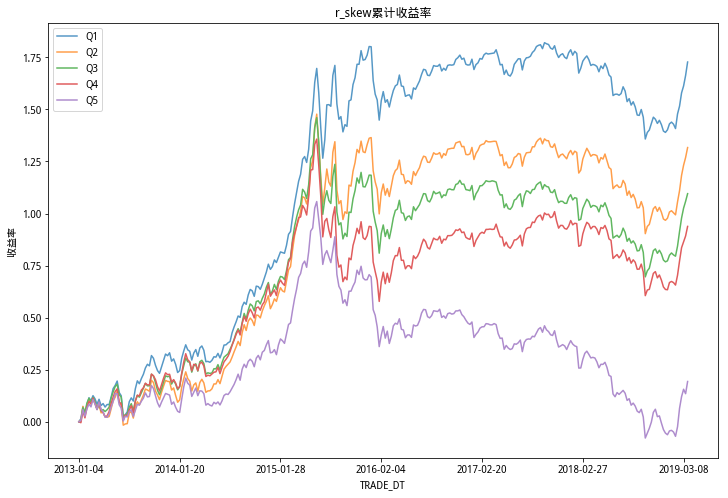
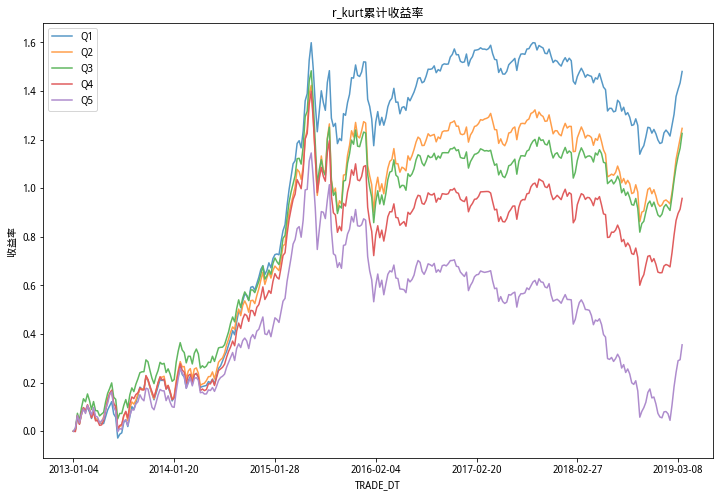
由以上累计收益率5档图看出,偏度RSkewRSkew因子分档很明显,单调性显著;RVolRVol因子分档不明显,峰度RKurtRKurt因子的区分度比偏度RSkewRSkew略微弱一些,但好于RVolRVol因子。
和研报结论相同。
2 因子多空收益
# 展示某因子的多空收益率(Bull and Bear)
def show_factor_bb_return_rate(ret_df, factor_dict, factor_name):
color = ‘red’
label = ‘多空累计收益’
展开代码 ↓
# ‘r_vol’, ‘r_skew’, ‘r_kurt’
show_factor_bb_return_rate(ret_df, factor_dict, ‘r_vol’)
show_factor_bb_return_rate(ret_df, factor_dict, ‘r_skew’)
show_factor_bb_return_rate(ret_df, factor_dict, ‘r_kurt’)
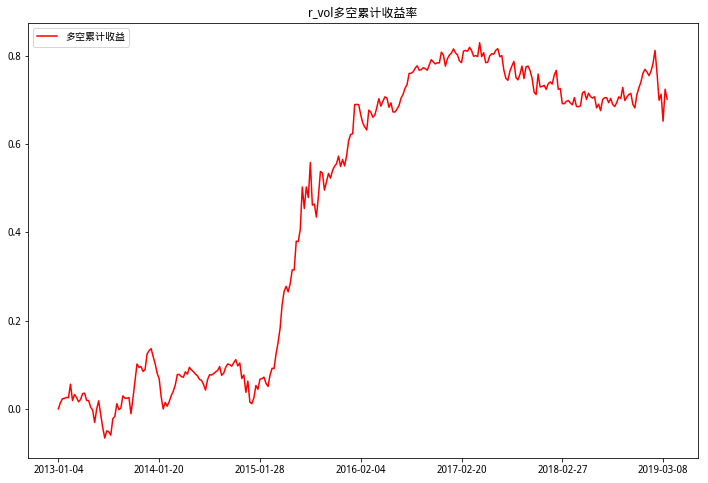
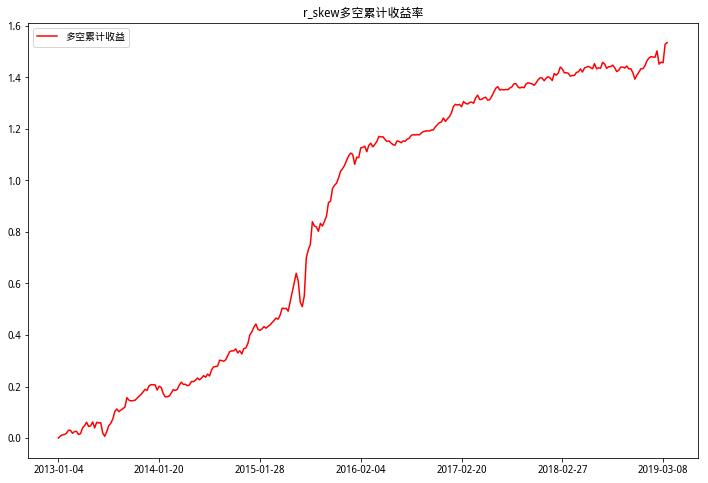
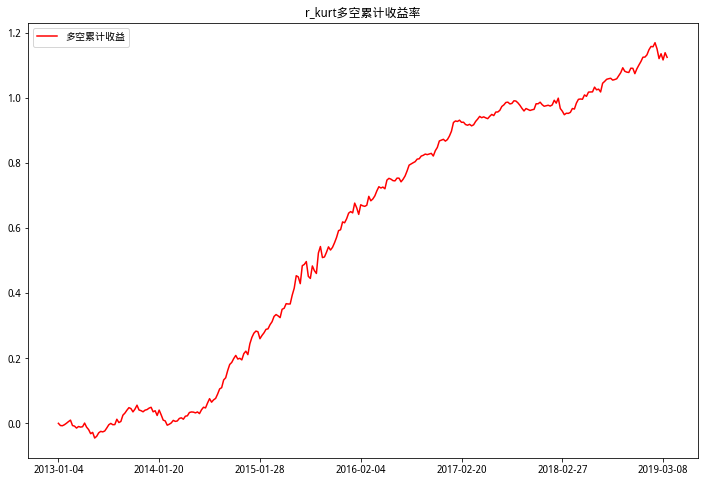
从以上多空累计收益三图可以看出,偏度RSkewRSkew因子多空收益最高,也比较稳定,基本上一直在上行,进一步验证了RSkewRSkew因子的有效性。峰度RKurtRKurt因子在2013-2014年多空收益在0上下徘徊,和峰度RKurtRKurt因子分档累计收益图中2013-2014区分度不明显情况相同。
3 因子IC
import scipy.stats as st
# 展示某因子的IC
def show_factor_ic(ret_df, factor_dict, factor_name):
color_list = [‘#2B4C80’, ‘#B00004’]
展开代码 ↓
# ‘r_vol’, ‘r_skew’, ‘r_kurt’
show_factor_ic(ret_df, factor_dict, ‘r_vol’)
show_factor_ic(ret_df, factor_dict, ‘r_skew’)
show_factor_ic(ret_df, factor_dict, ‘r_kurt’)
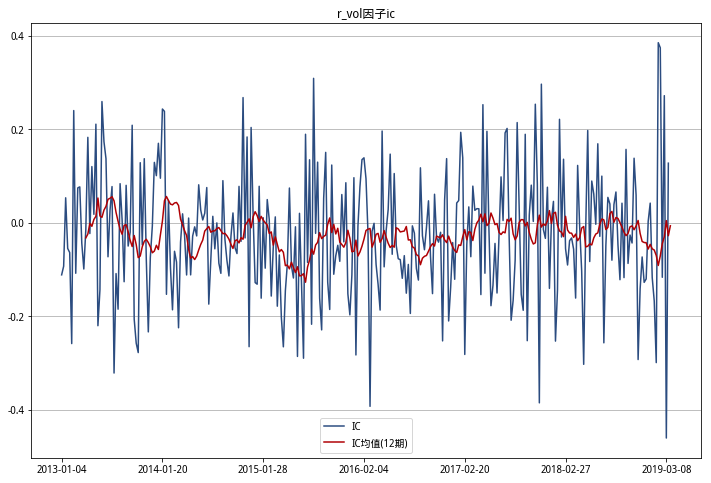
r_vol ic 小于0的个数占比:0.5973597359735974
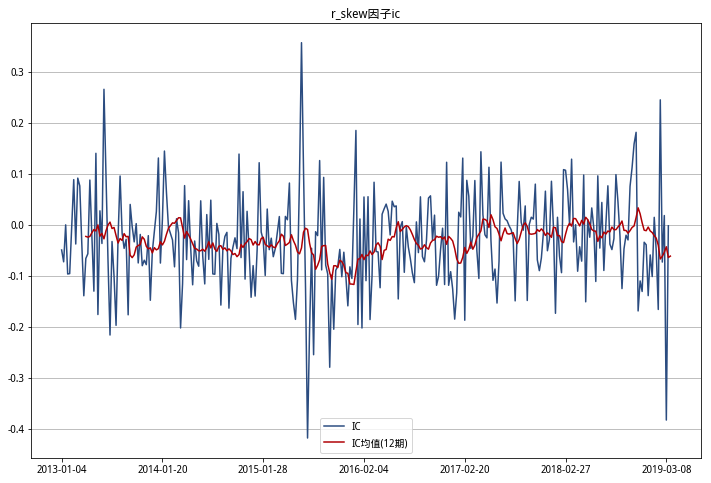
r_skew ic 小于0的个数占比:0.6600660066006601
r_kurt ic 小于0的个数占比:0.66996699669967
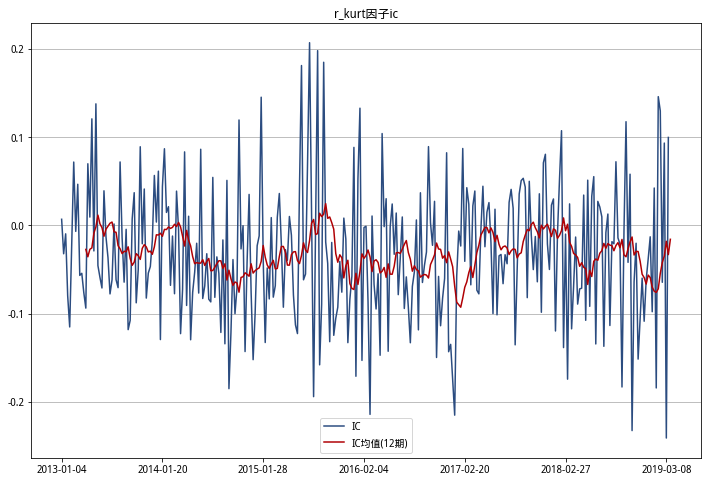
从以上IC三图可以看出,偏度RSkewRSkew因子平均IC基本都小于0,且IC负值占比超过6成,预测能力较好。
偏度RSkewRSkew因子在中证500指数下2013-2019年IC小于0的个数占比为66%,和研报中中证500的IC统计结果近似。受限于研究的内存和因子构建执行时间,我没有使用全市场数据计算,研报中全市场数据的IC小于0的个数占比未验证。
4因子换手率
# 展示某因子的换手率
def show_factor_turnover_rate(factor_dict, factor_name):
y_list = [[], []]
_\# 收益率折线图从0开始_**展开代码 ↓**
# ‘r_vol’, ‘r_skew’, ‘r_kurt’
show_factor_turnover_rate(factor_dict, ‘r_vol’)
show_factor_turnover_rate(factor_dict, ‘r_skew’)
show_factor_turnover_rate(factor_dict, ‘r_kurt’)
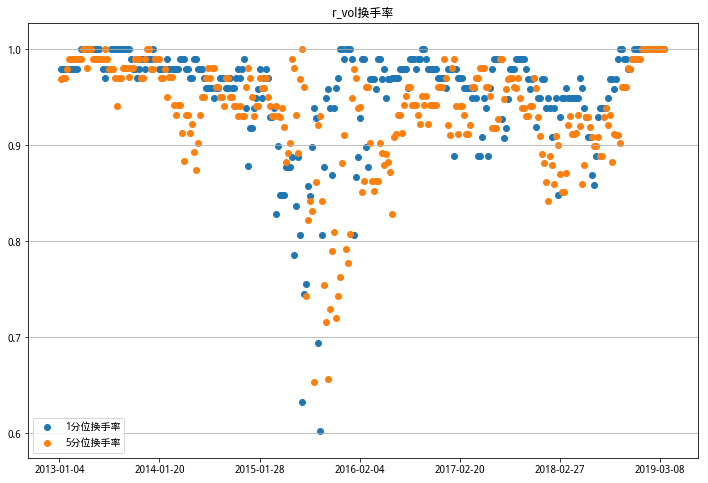
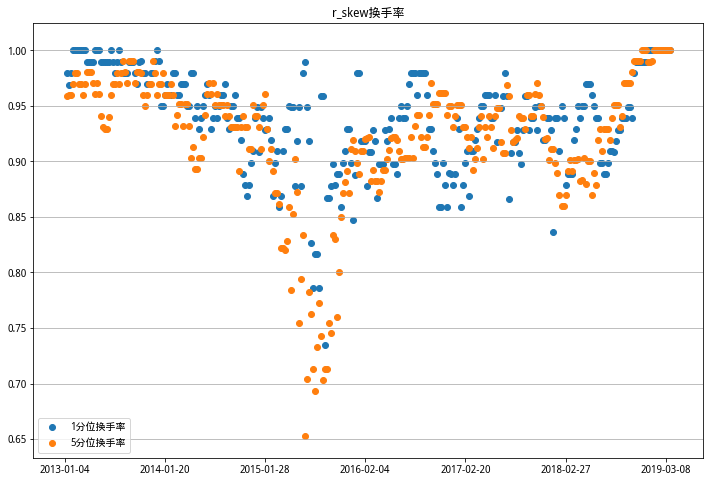
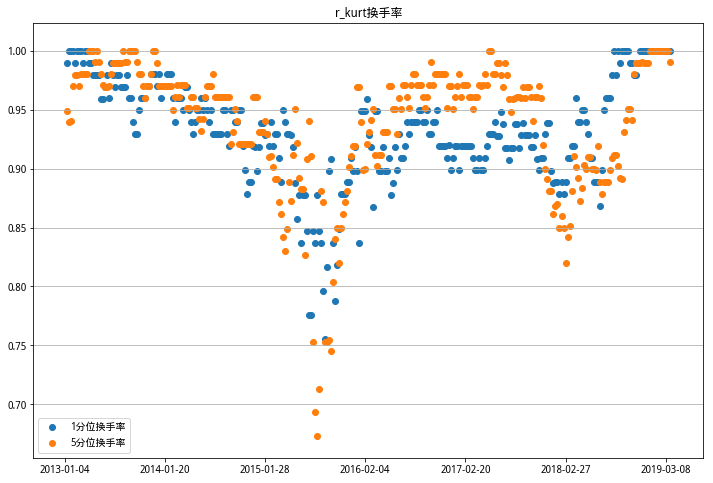
这里不知道换手率统计的对不对。我只考虑了两个调仓日之间,每个档位更换股票占原股票的比例。偏度RSkewRSkew因子的换手率比较稳定,基本上每期都要把持仓更换一遍,笑哭😹。看散点分布情况,换手率分布大部分在85%以上,考虑到时间选取和算法的不同,和研报中给出的平均80%换手率也算接近。
6总结
本研究从因子分布和因子百分位走势对因子特征做了展示,从累计收益率、多空收益、因子IC、换手率几个角度做实证分析。
总的来说,本研究使用中证500指数2013-2019年的数据选股,对研报中的内容基本上都做了复现,得出结论:三个因子中偏度RSkewRSkew因子最有效,分组区分度高,比较稳定,收益最高。复现得出的结论基本和研报一致,这篇研报还是挺靠谱的。
关注我的公众号春秋金经,联系作者,获得本篇文章中的全部代码、研报原文。